Vector Databases
Buzzword Rating: Load Bearing
Vector Databases are very important in the current AI landscape. Everything that ChatGPT or Claude Code has done to impress you is based on vectors.
I rate vector databases as Load Bearing because they are foundational to how AI works right now. We need to store vectors somewhere. This caused a wave of new vector database companies to come to the scene. Meanwhile, every existing database company has started marketing themselves as a vector database.
There are four concepts you need in order to understand what a vector database is and the importance of them:
- Vector
- Semantic meaning
- Embedding
- Database
Vector
A vector is a list of numbers. That's it.
[0.4, 0.1] -- two dimensions
[0.2, 0.8, 0.4, 0.1] -- four dimensions
Vectors used in modern LLMs run in the 1,536 to 4,096 dimension range. So more like:
[0.3, 0.9, 0.1, ...]
Semantic Meaning

Semantic means the meaning and interpretation of words in context.
Take the word "chip." Put it next to different words and it becomes a completely different object:
- Nacho chip
- Fish and chips
- Chip on your shoulder
- Golf chip shot
- Poker chip
- NVIDIA chip
Same word. Completely different meaning. That's semantics.
Embedding
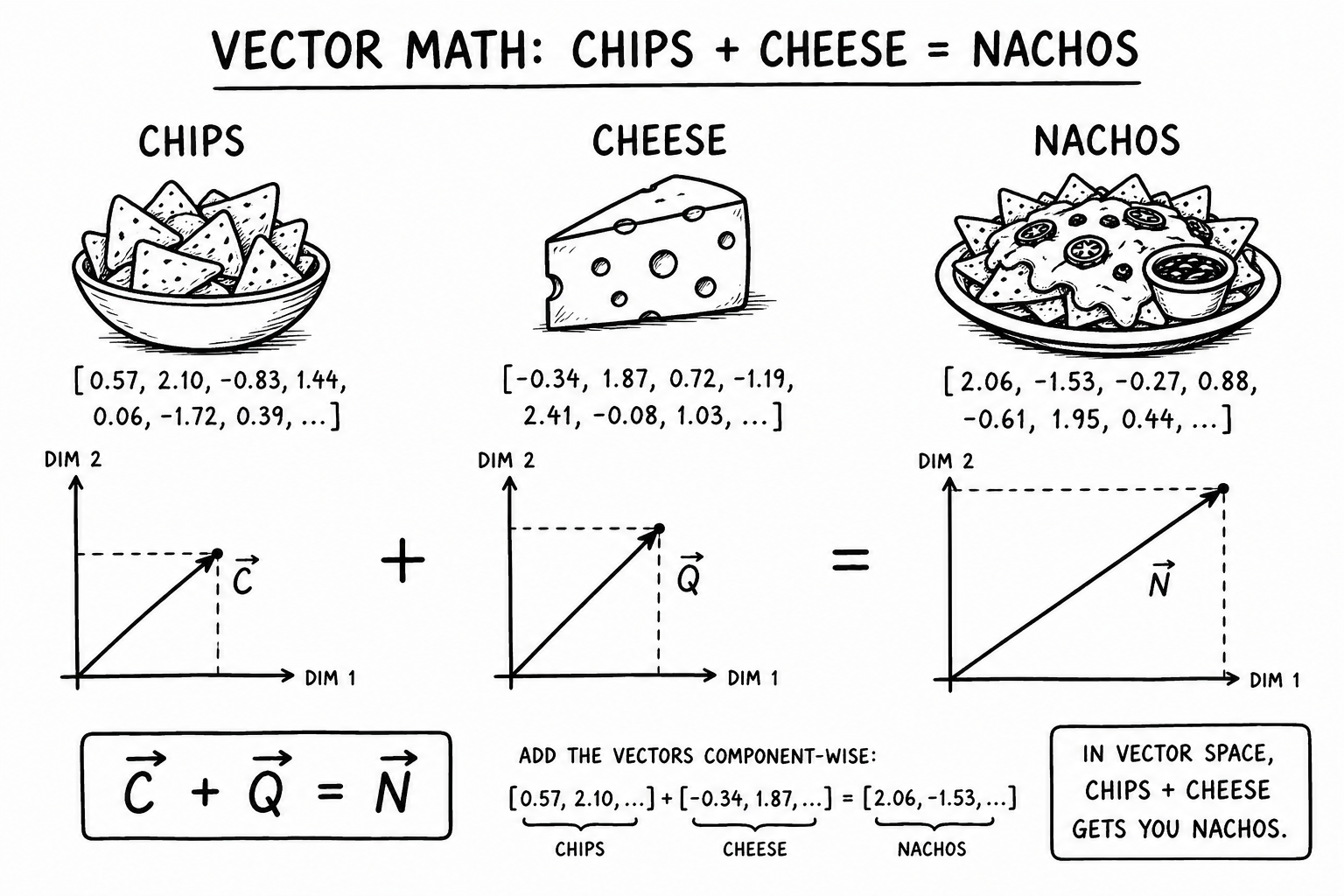
The embedding process takes a word and converts it into a vector that captures its semantic meaning. Once you have vectors, you can run math on them.
The classic example: king - man + woman = queen
A better one: chips + cheese = nachos
Words with similar meanings end up near each other in vector space. Empanadas, calzones, samosas, bao, pasties, pierogies... they all cluster together. They're all variations on the same idea: dough wrapped around filling.
This is extremely powerful. If we generated embeddings for every word in the English language, we could simulate a high degree of inteligence. But when we've embedded everything ever posted to Reddit, we can start to see much deeper hidden meanings that tie the entire world together.
Vector Databases
Now we have trillions of vectors and more being generated every second. They represent Reddit comments, product descriptions, support tickets, legal documents, quite literally everything you've ever heard of. You need somewhere to put them.
That's the vector database.
The Bolt-On Approach
Existing databases only need two things to handle vectors:
- A vector data type
- An index optimized for vector search
Here's what a standard table looks like:
| id (integer) | food (string) |
|---|---|
| 1 | chips |
| 2 | cheese |
| 3 | nachos |
| 4 | empanada |
| 5 | pupusa |
| 6 | samosa |
| 7 | bao |
| 8 | pot pie |
Here's what a bolt on looks like:
| id (int) | food (string) | vector (vector) |
|---|---|---|
| 1 | chips | [0.57, 2.10, -0.83, 1.44, 0.06, -1.72, 0.39, ...] |
| 2 | cheese | [-0.34, 1.87, 0.72, -1.19, 2.41, -0.08, 1.03, ...] |
| 3 | nachos | [2.06, -1.53, -0.27, 0.88, -0.61, 1.95, 0.44, ...] |
| 4 | empanada | [-1.78, 0.33, 1.60, -0.94, 0.17, 2.29, -0.70, ...] |
| 5 | calzone | [-1.81, 0.29, 1.55, -0.98, 0.21, 2.31, -0.67, ...] |
| 6 | samosa | [-1.74, 0.37, 1.63, -0.89, 0.14, 2.25, -0.73, ...] |
| 7 | bao | [-1.83, 0.31, 1.58, -0.97, 0.20, 2.34, -0.65, ...] |
| 8 | pot pie | [-1.76, 0.35, 1.57, -0.91, 0.19, 2.27, -0.72, ...] |
The databases that have gone this route:
| Database | Their branding |
|---|---|
| PostgreSQL | pgvector |
| MySQL | VECTOR |
| Redis | Vector Search |
| Oracle | Vector |
| MongoDB | Atlas Vector Search |
Vector-First Databases
Then there are databases built for vectors from the start:
| Database | Model |
|---|---|
| Pinecone | Fully managed |
| Milvus | Open source + cloud |
| Weaviate | Open source + cloud |
| ChromaDB | Lightweight / local |
The Main Query: Nearest Neighbor Search
The primary thing you do with a vector database is ask "what's closest to this?"
results = index.query(
vector=empanada.vector,
top_k=3
)
top_k means: only give me the k most similar results.
Query for empanada, get back:
- Calzone
- Samosa
- Bao
This is called a nearest neighbor search, and it's how semantic search works under the hood.
Search Types
- Semantic search find things with similar meaning, not just matching words
- Lexical search traditional keyword matching
- Hybrid both, blended together
The Indexing Problem
Indexing adds efficiency to database queries. With standard text/numeric fields, there have been many fiscal years, life-persuits, dissertations dedicated to improving the quality and speed of the queries.
Efficiently Indexing in a multi-dimensional vector space makes all that work above seem easier tha baking a frozen pizza.
The good news is that indexing is already quite efficient, and from my and your perspective, very easy. Using vectors in your product today is cheap compared to what it would have cost even a year ago.
So Which One Do You Use?
The vector-first databases offer incredible scaling capabilities. The bolt-on options are plenty capable if you're just looking to get off the ground. If you have no idea where to start, start with PGVector. It's open source, well documented, and well resourced!